
First Published: First Break, February 2023
Keyla Gonzalez, Olga Brusova and Alejandro Valenciano describe a machine learning workflow to predict missing data in well logs at the basin scale.
Summary
Log data recorded by wireline tools are incomplete in most well locations. Vital information often needs to be predicted to precisely characterize the Earth’s subsurface. Here we describe a machine learning (ML) workflow to predict missing data in well logs at the basin scale. The ML models produce outstanding results when adequate quality data is provided for the model training and inference. Using examples from the Permian Basin in the US, we illustrate the use of the automated data clean-up pipeline and the clean-up impact on ML algorithm training and prediction. The ML models achieve a prediction quality of 90% to 95% in a blind test containing 679 wells if trained on clean data from the Permian Basin.
Introduction
Wireline logs are an integral component in characterizing subsurface properties. For economic reasons, data from specific logs or depth intervals are not collected, resulting in incomplete information from the surface to the base of the well in most locations. An alternative that addresses the lack of data is to create synthetic curves. With the availability of millions of digitized wells with a wide spatial distribution and the recent advances of data science, the prediction of missing logs or missing log intervals with machine learning (ML) algorithms is now possible. Data preparation and clean-up are fundamental steps before ML algorithms training and inference. In conventional petro-physical or geophysical workflows, log data clean-up is done manually, one well at a time. The clean-up tasks include, but are not limited to, verifying information in the LAS files, curve categorization, units’ standardization, log splicing, and log spatial normalization. The manual approach to well log clean-up is not scalable, as training ML algorithms requires extensive data. To create practical ML tools for well log prediction, we first need to develop an automated pipeline for well log cleaning.
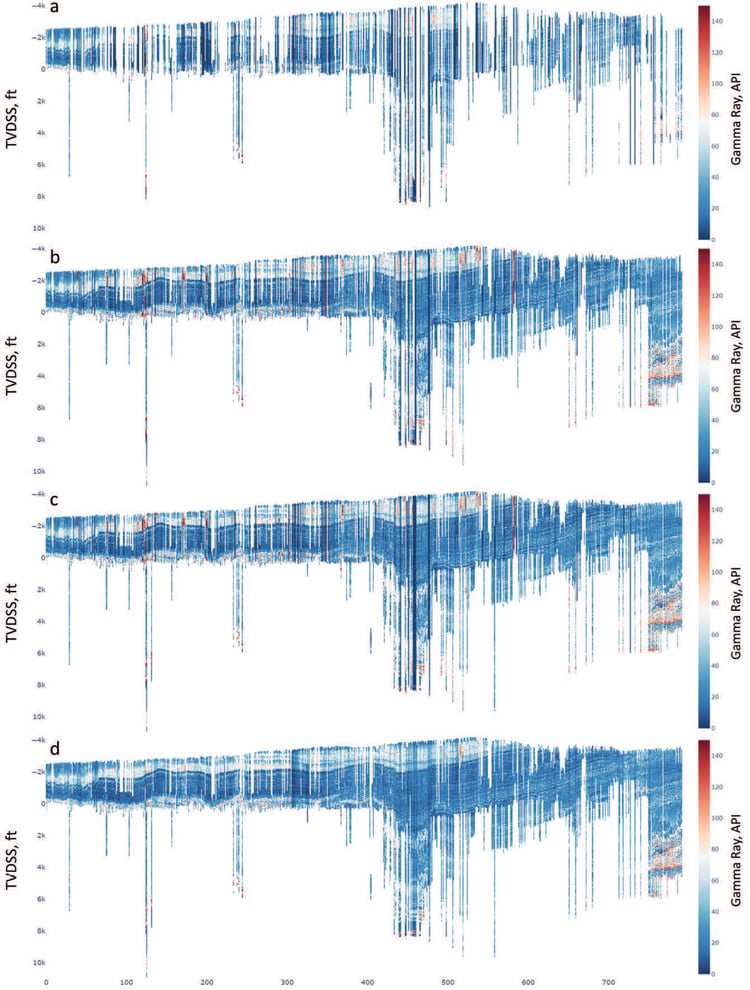
Change in the state of an arbitrary gammaray cross section in the Permian Basin during the
clean-up workflow. (a) Shows data with common mnemonics and standard units. (b) Shows the same
data after more rigorous mnemonic analyses, fixing mnemonic clashes, checking, and fixing unit issues.
Due to thorough mnemonic and unit quality control, several logs are added to the cross-section. (c)
Shows the effect of log merging from different runs. The wells have better depth coverage. (d) Shows
the effect of basin-scale log normalization. Most artificially high and low gamma-ray values present in
4c are fixed in 4d.
This paper presents an end-to-end machine learning workflow for well logs prediction at a basin scale...
<continued>
Download the full article using the link at the top of this page.
The results detailed in this article are available to clients through TGS's eCommerce platform, R360.